Results | Updates | Usage | Todo | Acknowledge


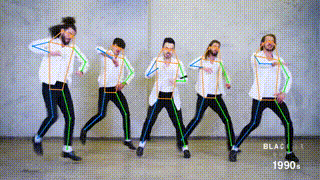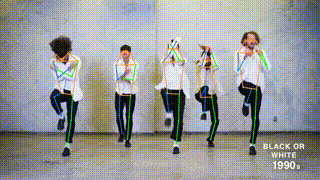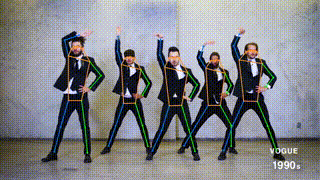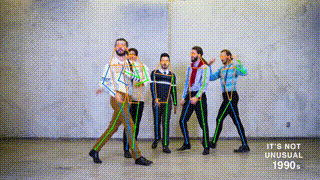
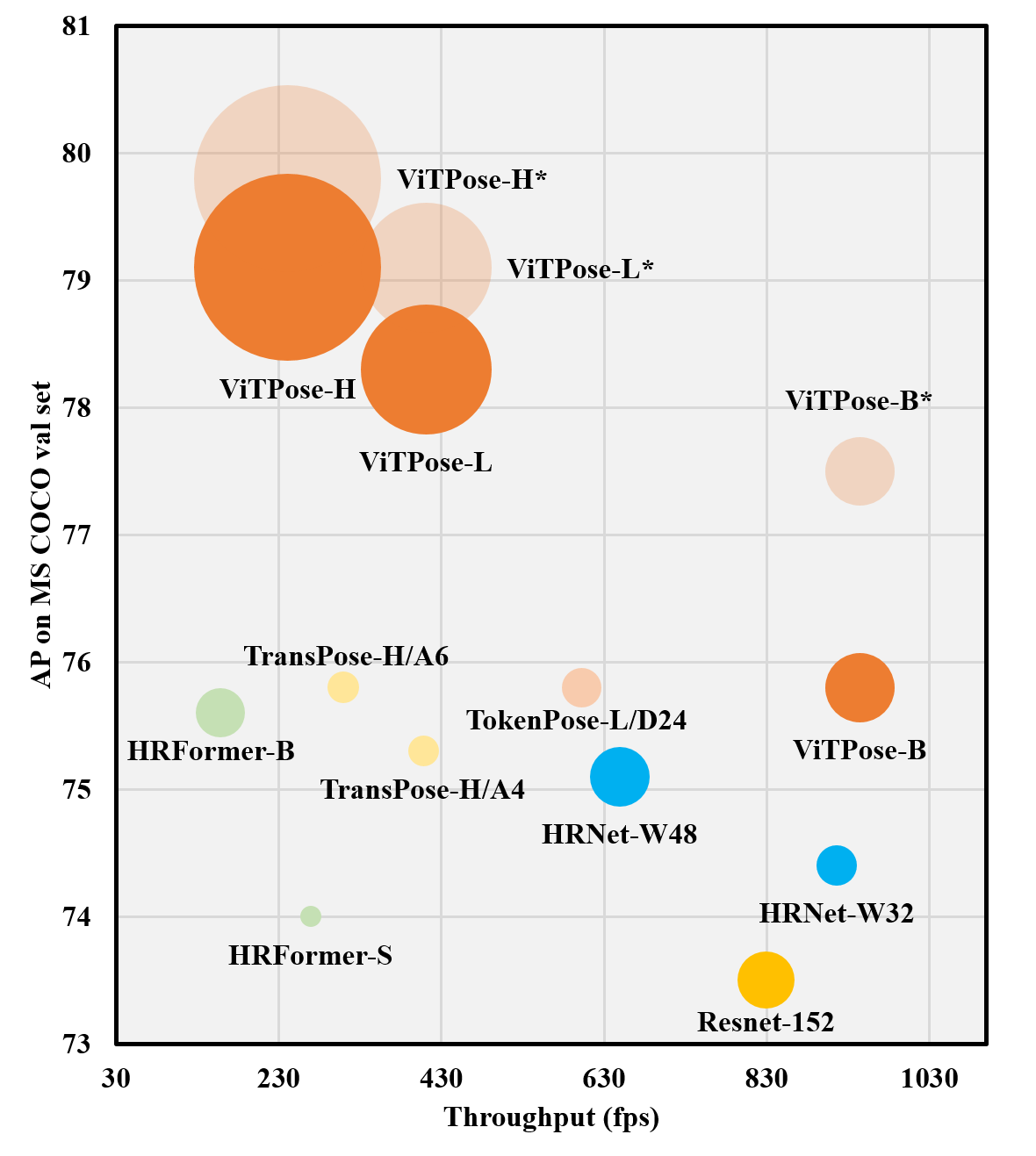 ## Results from this repo on MS COCO val set (single-task training)
Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
> With classic decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
> With simple decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
## Results from this repo on MS COCO val set (multi-task training)
Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 81.0 | 85.6 | | |
## Results from this repo on OCHuman test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 93.3 | 94.3 | | |
## Results from this repo on CrowdPose test set (multi-task training)
Using YOLOv3 human detector. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AP(H) | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 78.3 | 67.9 | | |
## Results from this repo on MPII val set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
| Model | Dataset | Resolution | Mean | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 94.3 | | |
## Results from this repo on AI Challenger test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 43.2 | 47.1 | | |
## Updates
> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
> [2022-05-06] Upload the logs for the base, large, and huge models!
> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
## Usage
We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
```bash
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
git checkout v1.3.9
MMCV_WITH_OPS=1 pip install -e .
cd ..
git clone https://github.com/ViTAE-Transformer/ViTPose.git
cd ViTPose
pip install -v -e .
```
After install the two repos, install timm and einops, i.e.,
```bash
pip install timm==0.4.9 einops
```
Download the pretrained models from [MAE](https://github.com/facebookresearch/mae) or [ViTAE](https://github.com/ViTAE-Transformer/ViTAE-Transformer), and then conduct the experiments by
```bash
# for single machine
bash tools/dist_train.sh
## Results from this repo on MS COCO val set (single-task training)
Using detection results from a detector that obtains 56 mAP on person. The configs here are for both training and test.
> With classic decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | MAE | 256x192 | 75.8 | 81.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) | [log](logs/vitpose-b.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSMjp1_NrV3VRSmK?e=Q1uZKs) |
| ViTPose-L | MAE | 256x192 | 78.3 | 83.5 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [log](logs/vitpose-l.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSd9k_kuktPtiP4F?e=K7DGYT) |
| ViTPose-H | MAE | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [log](logs/vitpose-h.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgShLMI-kkmvNfF_h?e=dEhGHe) |
> With simple decoder
| Model | Pretrain | Resolution | AP | AR | config | log | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | MAE | 256x192 | 75.5 | 80.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_simple_coco_256x192.py) | [log](logs/vitpose-b-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSRPKrD5PmDRiv0R?e=jifvOe) |
| ViTPose-L | MAE | 256x192 | 78.2 | 83.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_simple_coco_256x192.py) | [log](logs/vitpose-l-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSVS6DP2LmKwZ3sm?e=MmCvDT) |
| ViTPose-H | MAE | 256x192 | 78.9 | 84.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_simple_coco_256x192.py) | [log](logs/vitpose-h-simple.log.json) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSbHyN2mjh2n2LyG?e=y0FgMK) |
## Results from this repo on MS COCO val set (multi-task training)
Using detection results from a detector that obtains 56 mAP on person. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 77.5 | 82.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_base_coco_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 79.1 | 84.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_large_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 79.8 | 84.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/ViTPose_huge_coco_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 81.0 | 85.6 | | |
## Results from this repo on OCHuman test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 88.2 | 90.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_base_ochuman_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSrlMB093JzJtqq-?e=Jr5S3R) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 91.5 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_large_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTBm3dCVmBUbHYT6?e=fHUrTq) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 91.6 | 92.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/ochuman/ViTPose_huge_ochuman_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS5rLeRAJiWobCdh?e=41GsDd) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 93.3 | 94.3 | | |
## Results from this repo on CrowdPose test set (multi-task training)
Using YOLOv3 human detector. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AP(H) | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 74.7 | 63.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_base_crowdpose_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgStrrCb91cPlaxJx?e=6Xobo6) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 76.6 | 65.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_large_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTK3dug-r7c6GFyu?e=1ZBpEG) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 76.3 | 65.6 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/crowdpose/ViTPose_huge_crowdpose_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS-oAvEV4MTD--Xr?e=EeW2Fu) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 78.3 | 67.9 | | |
## Results from this repo on MPII val set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation. The metric is PCKh.
| Model | Dataset | Resolution | Mean | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 93.4 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_base_mpii_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSy_OSEm906wd2LB?e=GOSg14) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 93.9 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_large_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTM32I6Kpjr-esl6?e=qvh0Yl) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 94.1 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/mpii/ViTPose_huge_mpii_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTT90XEQBKy-scIH?e=D2WhTS) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 94.3 | | |
## Results from this repo on AI Challenger test set (multi-task training)
Using groundtruth bounding boxes. Note the configs here are only for evaluation.
| Model | Dataset | Resolution | AP | AR | config | weight |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: |
| ViTPose-B | COCO+AIC+MPII+CrowdPose | 256x192 | 31.9 | 36.3 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) |[Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgSlvdVaXTC92SHYH?e=j7iqcp) |
| ViTPose-L | COCO+AIC+MPII+CrowdPose | 256x192 | 34.6 | 39.0 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgTF06FX3FSAm0MOH?e=rYts9F) |
| ViTPose-H | COCO+AIC+MPII+CrowdPose | 256x192 | 35.3 | 39.8 | [config](configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/aic/ViTPose_base_aic_256x192.py) | [Onedrive](https://1drv.ms/u/s!AimBgYV7JjTlgS1MRmb2mcow_K04?e=q9jPab) |
| ViTPose-G | COCO+AIC+MPII+CrowdPose | 576x432 | 43.2 | 47.1 | | |
## Updates
> [2022-05-24] Upload the single-task training code, single-task pre-trained models, and multi-task pretrained models.
> [2022-05-06] Upload the logs for the base, large, and huge models!
> [2022-04-27] Our ViTPose with ViTAE-G obtains 81.1 AP on COCO test-dev set!
> Applications of ViTAE Transformer include: [image classification](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Image-Classification) | [object detection](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Object-Detection) | [semantic segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Semantic-Segmentation) | [animal pose segmentation](https://github.com/ViTAE-Transformer/ViTAE-Transformer/tree/main/Animal-Pose-Estimation) | [remote sensing](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Remote-Sensing) | [matting](https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting) | [VSA](https://github.com/ViTAE-Transformer/ViTAE-VSA) | [ViTDet](https://github.com/ViTAE-Transformer/ViTDet)
## Usage
We use PyTorch 1.9.0 or NGC docker 21.06, and mmcv 1.3.9 for the experiments.
```bash
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv
git checkout v1.3.9
MMCV_WITH_OPS=1 pip install -e .
cd ..
git clone https://github.com/ViTAE-Transformer/ViTPose.git
cd ViTPose
pip install -v -e .
```
After install the two repos, install timm and einops, i.e.,
```bash
pip install timm==0.4.9 einops
```
Download the pretrained models from [MAE](https://github.com/facebookresearch/mae) or [ViTAE](https://github.com/ViTAE-Transformer/ViTAE-Transformer), and then conduct the experiments by
```bash
# for single machine
bash tools/dist_train.sh